[Ed. Note: Please welcome University of Texas Law Professor John Greil as our Guest Blogger. – GL]
Neal Katyal’s TED Talk detailing the role of AI in the tariffs case has drawn substantial attention in the legal world, including an annotated transcript; Bloomberg Law reporting the “blowback,” and David Lat providing an on-the-record response from Mr. Katyal.
I’d like to dig into an aspect I haven’t seen receive as much attention: what exactly did the AI do to help prepare Katyal, and how did it do it? This is meant to be a bit of a deep dive for LLM nerds and those who are AI-pilled.
I approach these questions from the perspective of someone who has built AI tools for appellate argument preparation. So I’ve thought about these particular problems. Bartolus.law generates an interactive dashboard and prep report tailored to circuit panel, subject matter, and briefs. In building it, I’ve had dozens of trial-and-error lightbulbs about what has worked, and what hasn’t.
Having spent that time, there are some odd passages in the TED Talk describing what Katyal did, and what it produced that jumped out to me.
So in this post I’d like to highlight some of those passages, and try to ask some questions that would add some clarity.
What do we know about how “Harvey Moot” works?
In his X post promoting the TED Talk, Katyal said:
Harvey predicted many of the questions the Justices asked — sometimes almost word for word. Brilliant. Tireless. Occasionally insufferable.
Here’s the catch: Harvey isn’t a person.
Harvey is a bespoke AI I built over the last year with a legal AI company, trained on every question every Justice has asked in oral argument for 25 years, and everything they’ve ever written.
There was a bit more detail in the actual talk. From what I can tell, this is all of the meat on how it works, and how it was trained:
- “Harvey reads the 200th tariff case the same way as he reads the first.”
- “Harvey is an AI. A bespoke system I’d been building with a legal AI company for the last year.”
- “I trained it on every question asked by a Supreme Court justice in the last 25 years and everything they’ve written, every opinion, every concurrence, every dissent, every separate opinion.”
- “And in that, patterns emerged.”
- “It predicted the contours of the very argument I would face.”
- “Harvey taught me peripheral vision: the idea [that] if you read a lot, you can see patterns and come up with stuff and anticipate the angles of attack before it arrived.”
- “It knew that Justice Gorsuch would ask me about the taxing power. It knew Justice Kavanaugh was going to grill me on tariffs versus embargoes. It nailed Justice Barrett’s worry about tariff refunds.”
- “It didn’t just predict his question, it predicted a possible escape route.”
- “Harvey even predicted Justice Gorsuch’s separate opinion, striking down the tariffs, almost verbatim.”
- “It’s almost verbatim.” (re: the Barrett license fee slide)
- “Harvey was not some god, it was our sparring partner — brilliant, tireless, occasionally insufferable — but not a god. Harvey asked the questions, we found the answers.”
- “Justice Barrett asked a question that Harvey hadn’t predicted.”
- “It didn’t just predict his question, it predicted a possible escape route. How the Chief Justice could vote for us and at the same time protect the institution he had spent his entire career defending.”
- “Harvey glimpsed that narrow door, I held the door open, the Chief Justice walked through it.”
- “A month before the argument, Harvey told me that I should expect a question from Justice Barrett about license fees.”
There’s a lot here that raises questions. Harvey describes itself as an “AI platform,” not a frontier foundation model like OpenAI’s GPT models, Anthropic’s Claude models, or Google’s Gemini models. And it is unclear whether Katyal’s build used one model family, several, or something more bespoke.
More importantly, the talk does not explain how Harvey turned 25 years of Supreme Court data (maybe around 120 million tokens) into actionable insights. Nor are we shown the full set of outputs Harvey produced. Without that, it is hard to tell what is being described.
So here are the questions I have about the technical aspects of what Katyal described:
1. What did Harvey actually predict from Chief Justice Roberts?
Most of the talk is framed as preparation for the oral argument. Katyal puts up a predicted question for Justices Gorsuch, Kavanaugh, and Barrett. But that’s followed with: “And the Chief Justice? It didn’t just predict his question, it predicted a possible escape route. How the Chief Justice could vote for us and at the same time protect the institution he had spent his entire career defending. Harvey glimpsed that narrow door, I held the door open, the Chief Justice walked through it, writing a six-to-three opinion, striking down the tariffs.”
“It didn’t just predict his question” implies that it actually did predict his question…but this particular question is not shown to the viewer.

It looks like here, Katyal is not referring to a question from the Chief, but Harvey predicting that he would agree with the plaintiffs on their main theory of the case.
On this point, the Chief’s opinion for the court actually closely tracked the D.D.C. opinion of Judge Contreras in the Learning Resources case: “Nor does IEEPA include language setting limits on any potential tariff-setting power. Every time Congress delegated the President the authority to levy duties or tariffs in Title 19 of the U.S. Code, it established express procedural, substantive, and temporal limits on that authority. E.g., 19 U.S.C. § 2132. For one example, Section 122 of the Trade Act of 1974 authorizes the President to impose an “import surcharge . . . in the form of duties . . . on articles imported into the United States” to “deal with large and serious United States balance-of-payments deficits,” but those tariffs are capped at 15 percent and can last only 150 days without Congressional approval. Id. § 2132(a).”
That language, unsurprisingly, closely tracks the preliminary injunction motion from the plaintiffs.
That injunction, as Blackman mentioned, was obtained by a trial team from Akin Gump led by Pratik Shah.
So what exactly did Harvey predict of the Chief? Any particular questions? The result? (It’s worth noting that as a “product” predicting oral argument questions and predicting outcome votes would seem to me completely different.).
If the ultimate upshot from Harvey is that “the Chief is an institutionalist,” then it’s unclear whether that comes from commentary or the corpus. That characterization is common in legal commentary, or legal scholarship (and even scholarship outside of law journals). (Another question: Did the “profiles” for the Justices include legal commentary? Or was the universe limited to the opinions and transcripts provided?)
2. How was the system actually trained?
According to the TED Talk, Katyal says: “I trained it on every question asked by a Supreme Court justice in the last 25 years and everything they’ve written, every opinion, every concurrence, every dissent, every separate opinion.”
That’s an interesting claim.
Because that is a LOT of data. My estimate from Claude placed that as something like 120 million “tokens.”
[Technical note: LLMs read text by breaking it down into “tokens.” The counts vary by model – “justice” might be one token as a common word; “unconstitutional” might be broken into “un” and “constitutional” or with current models a single token as a common enough word. “IEEPA” even though it’s shorter, probably registers as multiple tokens because it’s an unusual acronym that the underlying models weren’t trained on.]
Public frontier models now range from roughly 200,000 tokens to 1 million tokens or more, depending on the model and product tier. Consumer chat interfaces may limit the user to a smaller context window than the underlying model supports; API access or enterprise deployments sometimes expose the larger window. But even at 1 million tokens, 25 years of Supreme Court opinions and transcripts is way beyond that.
A context window is how much “stuff” the LLM can consider at one time. It’s sometimes described as like a reading desk. The desk can only fit so many papers and briefs on it, spread out and readable. Once it’s full, you need to take something off in order to add something new.
With an LLM, if you shove too much info into it, it can’t read all of it at one time. So it needs to use some process to deal with that problem.
One option is Retrieval-Augmented Generation – “retrieval” or “RAG.” For this, the model doesn’t actually “learn” from all the information you give it. It stores everything in a searchable index, then when you ask it a question, it tries to find the most relevant passages, and put those into the context window. In a simple vector-RAG system, the corpus is chunked, embedded, and searched for semantically similar passages. More advanced retrieval systems search the source documents in several ways, filter by metadata like court, date, Justice, or issue, rerank the best matches, and then give those passages to the model as context.
Retrieval tries to find passages that are similar to what you ask. A simple RAG setup retrieves relevant examples without estimating how representative those examples are. A better system can add metadata, classification, and aggregation to ask how often a Justice raises a category of concern in comparable cases. Retrieval is good at finding examples. But if the AI is predicting, that requires counting, classifying, or otherwise analyzing the whole data universe.
So which was Katyal’s system using? Simple RAG? A more sophisticated retrieval-and-analysis system? Something else entirely?
A second way is fine-tuning. Fine-tuning changes the model’s weights using training examples, usually prompts paired with desired outputs, so the model becomes more likely to produce the desired behavior. Not unlike a junior associate learning a task by showing her a bunch of examples: when the input looks like this, the answer should look like that. (Except the model doesn’t understand why it gives that output; it just matches the pattern.)
I think to most ears, the statement that Katyal “”trained it on every question and every opinion” connotes the idea of fine-tuning. If Harvey really fine-tuned the model, that would be a pretty impressive feat – one worth detailing.
It would involve defining the training objective, preparing examples, deciding what the input and target output are, cleaning transcripts, separating questions from answers, tagging Justice/question metadata, handling the differences between argument transcripts and opinions, and evaluating whether the tuned model outperformed a base model plus retrieval. That is going to take significant man hours, and a fair amount of time and management.
Fine-tuning would still have some downsides – it would likely result in a black box, where even if it were able to predict, you could probably not trace those predictions back to understand why they were made. The model’s prediction could be right, right for the wrong reasons, or wrong. And you might not be able to tell until it’s too late.
A third possibility is pre-computation. That would involve someone or something going through the archive and extracting specific features from each question (and presumably from the opinions as well – again, unclear how those different types of data were incorporated). The model then works from those extracted features instead of the raw text. Given the description in the TED Talk, it doesn’t sound like Harvey was deploying this kind of human (or AI) filter on the front end – but it would be good to know if they did!
3. What patterns emerged?
“And I trained it on every question asked by a Supreme Court justice in the last 25 years and everything they’ve written, every opinion, every concurrence, every dissent, every separate opinion. And in that, patterns emerged. It predicted the contours of the very argument I would face.”
So…what patterns emerged? What was the process for that? Can those be shared?
More importantly – are these patterns that aren’t already known to the Supreme Court bar or the general public? SCOTUS is the most studied court on earth. There are hundreds of attorneys focused on what the Justices ask and how they ask it. If Harvey was actually going to help Katyal prepare, it ought to do it better than a human could (in another context, it would be good enough if it could do it cheaper. In a multi-billion dollar case like Learning Resources, that’s not an issue).
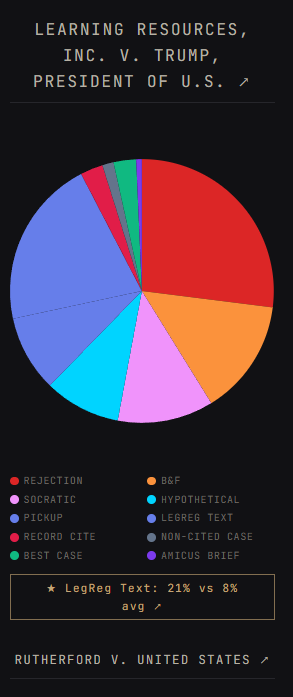
To take one example from the Bartolus dashboard, I can tell you that 21% of the questions in Learning Resources asked about statutory text, as opposed to only 8% of questions overall in OT 2025: More importantly – are these patterns that aren’t already known to the Supreme Court bar or the general public? SCOTUS is the most studied court on earth. There are hundreds of attorneys focused on what the Justices ask and how they ask it.
To take one example from the Bartolus dashboard, I can tell you that 21% of the questions in Learning Resources asked about statutory text, as opposed to only 8% of questions overall in OT 2025:
4. Did it read the briefs?
The oral argument in Learning Resources was on November 5, 2025. I only caught one time reference when describing the AI usage: “You know, a month before the argument, Harvey told me that I should expect a question from Justice Barrett about license fees.” So that’s about October 5.
The government filed its brief September 19. The challengers’ briefs were filed October 20.
The Algonquin point featured in the Federal Circuit’s opinion, and the government distinguished it in its opening brief.

So by October 5, an AI wouldn’t need 25 years of writings to realize licenses might come up: It could just read the lower court decision and the government’s brief. But if it pulled that question without either of those sources, that would be very impressive indeed. And it is notable that the AI correctly identified Justice Barrett as pursuing this line…until you see that “license” in various forms appeared over a hundred times in the oral argument, and was a focus of multiple Justices:

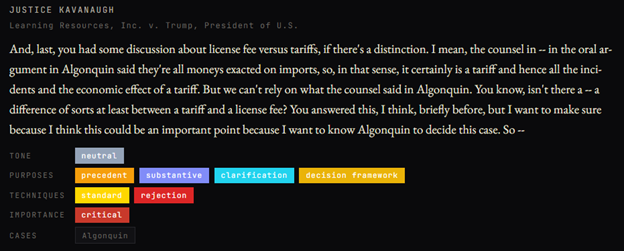
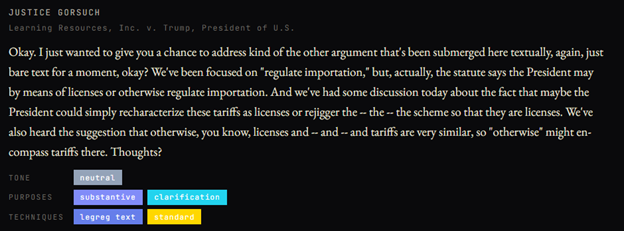

So what role did the briefs have?
And what about the almost four dozen amicus briefs – multiple of which were invoked during the oral argument?
5. What did it predict that no human predicted? What did it not predict, that was asked?
“It knew that Justice Gorsuch would ask me about the taxing power. It knew Justice Kavanaugh was going to grill me on tariffs versus embargoes. It nailed Justice Barrett’s worry about tariff refunds.”
“You know, at one moment in the argument, Justice Barrett asked a question that Harvey hadn’t predicted. And I remember it felt like she and I were the only two people in that marble and mahogany room. And in the half-second before I answered, I did something no algorithm can do. I looked at her. I really looked. I wanted to understand her worry. And I answered the worry.”
There’s a lot of data missing from the talk. We don’t really have the numerators (how many questions did the AI predict in all? How many were attributed to each Justice?) or denominators (how many were hits? How many were close?).
Predicting questions that every mooter predicted isn’t nothing. And that could prove a valuable tool for appellate practitioners who can’t assemble multiple moots with court experts.
But I think the real value would be: did we cover the bases, so that (almost) nothing caught us off guard? And did the AI predict any questions that no human mooter did?
–
Katyal has produced what is likely the most discussed legal TED Talk of all time. Buried in it are some fun puzzles about what he was actually doing with Harvey, and what the AI is capable of today.
If you know the answers to some of the questions above, please, I’d love to learn!